http://hadoopi.wordpress.com/2013/05/27/understand-recordreader-inputsplit/
File is composed on 6 lines of 50Mb each
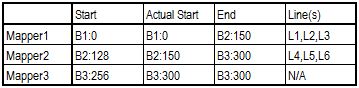
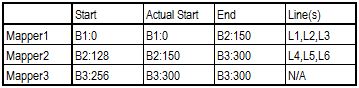
The first Reader will start reading bytes from Block B1, position 0. The first two EOL will be met at respectively 50Mb and 100Mb. 2 lines (L1 & L2) will be read and sent as key / value pairs to Mapper 1 instance. Then, starting from byte 100Mb, we will reach end of our Split (128Mb) before having found the third EOL. This incomplete line will be completed by reading the bytes in Block B2 until position 150Mb. First part of Line L3 will be read locally from Block B1, second part will be readremotely from Block B2 (by the mean of FSDataInputStream), and a complete record will be finally sent as key / value to Mapper 1.
The second Reader starts on Block B2, at position 128Mb. Because 128Mb is not the start of a file, there are strong chance our pointer is located somewhere in an existing record that has been already processed by previous Reader. We need to skip this record by jumping out to the next available EOL, found at position 150Mb. Actual start of RecordReader 2 will be at 150Mb instead of 128Mb.
We can wonder what happens in case a block starts exactly on a EOL. By jumping out until the next available record (through readLine method), we might miss 1 record. Before jumping to next EOL, we actually need to decrement initial “start” value to “start – 1″. Being located at at least 1 offset before EOL, we ensure no record is skipped !
Remaining process is following same logic, and everything is summarized in below table.


No comments:
Post a Comment